During my Machine Learning class we were tasked with implementing Google’s PageRank algorithm. This is the algorithm that Google uses (or well, the first algorithm they used) to rank the importance of sites for their search engine.
Now, what made this so interesting is that it turns out this algorithm can be applied to any set which has reciprocal references between elements. For example, you could take the set of Facebook users and treat a friendship as a link — now you can calculate the most “important” user on Facebook. Now the ideas started floating around my head, and my immediate thought was taking the set of members in a Discord server, and treating a mention (as in a user mentioning another user in a message) as a “link” between members, and figure out who is truly the most popular.
The Theory of PageRank
Our goal is to somehow figure out the order of the pages in terms of importance given a set of links between them. Consider three webpages each containing hyperlinks to other pages. If we draw an arrow indicating such a link, we can create the following graph:
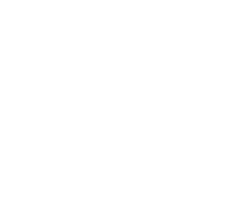
This graph shows that page 1 and 2 link to each other, and page 1 and 2 both link to page 3, and page 3 links to nothing. This is called a directed graph, where the vertices are pages and the edges are links. Additionally we refer to outgoing links as outlinks and incoming links as inlinks. If we then say that a link from page i to page j is worth one point, we can build a matrix which represents our links. If we fill out a 1 when an edge (i, j) that points from i to j exists and a 0 when it does not, we end up with the following matrix:
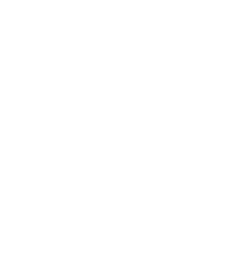
This type of matrix is called an adjacency matrix — specifically an asymmetrical adjacency matrix because the edges in our graph are directional, which results in our matrix being diagonally asymmetric.
Your first instinct might be to just sum the columns to get a score — and in an overly simplistic case like this that would actually work decently well. Page 1 and 2 would get a score of 1, while page 3 would get a score of 2, clearly indicating page 3 is the most important page. The reason this is problematic is that all links are assumed to be equally important, which they are not. A link from an important page (i.e. a page with many inlinks) is clearly more important than a link from a less important page (few inlinks).
Seeing this, the Google engineers came up with the concept of a “random surfer”. Imagine a person traversing the web completely at random through hyperlinks. If he started at page 1 he could jump to either page 2 or 3 from that state. If he jumps to page 2, then he has the option of jumping to either page 1 or 3. Continue this iterative process forever and you have a “random surfer”. The question the engineers wanted to answer was:
If the random surfer infinitely surfed the hyperlink structure of the web, which pages would he visit the most?
Turns out, this problem has been solved a long time ago for something called Markov chains.
Creating our Markov chain
Since our directed graph and adjacency matrix does not represent a Markov chain, we have to translate it to a Markov chain to exploit its properties. A Markov chain at its core describes a collection of states, in our case pages, and the transition probabilities of moving between them, in our case the probability our random surfer clicks a specific hyperlink.
The first modification we have to do is change our graph/matrix from simply signifying a link to instead representing the transition probability of that link being chosen. We can do this by simply dividing outlink values by the total amount of outlinks from that page:
Both page 1 and 2 have two outlinks, so each value in those pages’ row-vectors gets divided by 2 making the vector sum to 1 — which is a key property of Markov chains. With that said, the keen-eyed of you might have noticed that the row-vector of page 3 does not sum to 1. This is because page 3 has no outlinks. The work-around the Google engineers came up with in this situation was to replace all outlinks for such a page to 1/k where k is the number of pages.
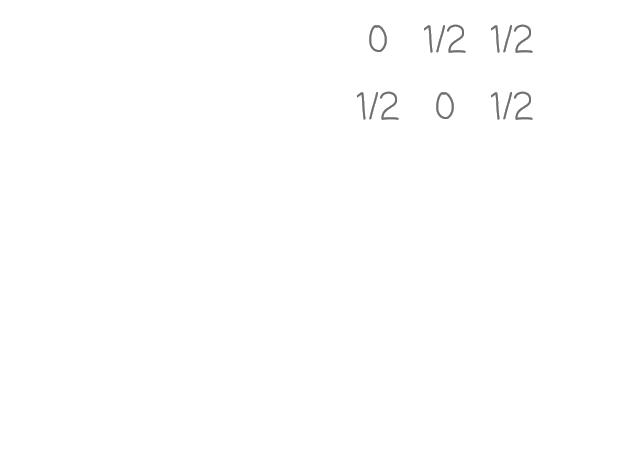
If you were a random surfer and landed at page 3, this would equate to simply jumping to a random page. If this modification was not made, our random surfer would be stuck at page 3 with nowhere to go.
The rightmost matrix is now our fully fledged Markov matrix, which describes transition probabilities of all possible jumps in our rightmost graph, which is our directed graph describing our Markov chain, which is what a random surfer would “surf”.
Calculating rankings
Now, we finally get to the magical part of this algorithm. We start by creating a vector of cardinality k, our page count, filled with random scalars. Then we transpose (flip diagonally) our Markov matrix and multiply it by our vector.
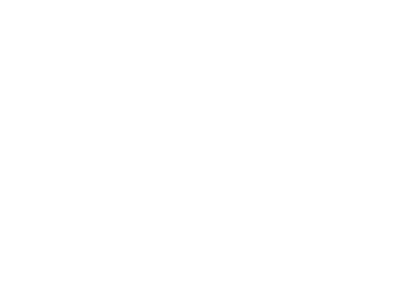
The resulting vector is the result of performing one iteration of something called the Power method, which is an algorithm which does exactly what we want, given we have a Markov matrix to perform it on. Since we are only interested in the direction of this resulting vector, we normalize it, and perform the next iteration by feeding it back into the same matrix multiplication.
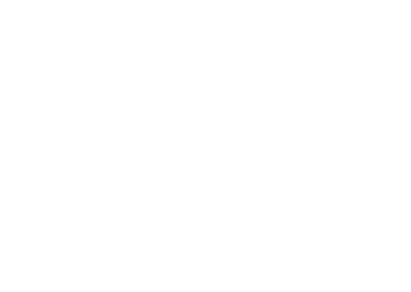
If we continue iterating until the results more or less converge…
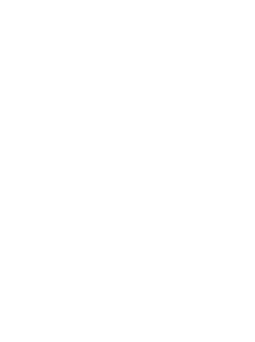
… we see some results! Higher values mean a higher relative importance compared to other indices. This can be interpreted as that the third element (third page) is the most significant, while the first and second page share a second place (equally significant). This intuitively makes sense, as the third page is the only page which has two inlinks, while the first and second page are both only linked to once. If you know how to do matrix multiplication, this might make sense on some level for you. If it doesn’t, simply disregard it as linear algebra magic, or investigate it yourself!
So, who is the most popular Discord member?
Well, step one is to collect some data — in this case we want to see which members mention who. This initial work only took ten minutes or so. I set up a quick table in my Postgres database and wrote a few quick lines of code to listen for messages, where if there are any mentions store these relations as a record.
@commands.Cog.listener()
async def on_message(self, message):
if message.author.bot:
return
if not message.mentions:
return
query = (
'INSERT INTO mention (guild_id, user_id, mention_id) '
'VALUES ($1, $2, $3)'
)
records = [
(message.guild.id, message.author.id, mention.id)
for mention in message.mentions if not mention.bot
]
await self.bot.db.executemany(query, records)This data can be used to build an adjacency matrix later on, where A[i, j] is the amount of messages by member i which mentions member j. I suspect this is gonna need a good chunk of data, so I’m gonna leave it collecting for a few weeks.
A few weeks later…

Nice! We managed to collect some 800 mentions. Funnily enough I forgot to filter out self-mentions when saving them, thus the last predicate in the SQL.
Lets fetch our data from the database, create a list of tuples indicating our links, and map each unique member id to an integer value we can use to index our matrix.
# fetch all records
records = await db.fetch(
'SELECT user_id, mention_id FROM mention WHERE guild_id=$1 AND user_id!=mention_id',
guild_id
)
# create a list of (user_id, mention_id) tuples
data = [
(record.get('user_id'), record.get('mention_id'))
for record in records
]
# get the set of all member ids
ids = set(itertools.chain(*data))
# create a dictionary which maps each
# unique member id to a unique index
id_map = {_id: idx for idx, _id in enumerate(ids)}With this data, we can now create our initial link matrix:
# amount of unique members
k = len(id_map)
# our matrix!
m = np.zeros(shape=(k, k))
# populate link matrix
for user_id, mention_id in data:
# get matrix indexes from the member ids
user_index = id_map[user_id]
mentioned_index = id_map[mention_id]
# increment the mention counter for this link
m[user_index, mentioned_index] += 1To perform the power method, the matrix needs to represent the transition matrix of a Markov chain, so we do the appropriate modifications discussed earlier.
# unit vector we can replace zerovectors with
e = np.full(k, 1 / k)
# for each vector in matrix
for i in range(k):
# find sum of row-vector
divisor = np.sum(m[i])
# if it's a zerovector, replace it
# with the unit vector we made above
if divisor == 0:
m[i] = e
# otherwise, we can divide by the sum
else:
m[i] = m[i] / divisorNow that we have our Markov matrix, we can start crunching numbers! I ripped some code from Wikipedia which we can use.
def power_method(matrix, num_simulations=100):
# random initial vector
b_k = np.random.rand(matrix.shape[1])
for _ in range(num_simulations):
# multiply the matrix by the vector
b_k1 = np.dot(matrix, b_k)
# normalize the vector
b_k = b_k1 / np.linalg.norm(b_k1)
return b_kLet’s call our power method and print the resulting rankings to our console.
ranks = power_method(m.transpose())
print(ranks)
# [0.02668324 0.09736238 ... 0.02717116 0.01892194]
# lets sort and print it!
sort = np.argsort(ranks)[::-1]
for idx in range(5):
_id = sort[idx]
print(f'Rank #{idx + 1} is user #{_id} with score {ranks[_id]}')The code above outputs the following:
Rank #1 is user #7 with score 0.530677050549618
Rank #2 is user #3 with score 0.31470159724507973
Rank #3 is user #16 with score 0.25773141652304865
Rank #4 is user #12 with score 0.24680117752553055
Rank #5 is user #17 with score 0.23106526130925578
We can see one user is distinctively more “important” than the rest, having a much higher score. We have one that’s a bit further back, followed by the rest of the members. Also, for fun, below is a video of the PageRank scores of the top 15 members plotted over time. You can see the rankings listed above at the end of the graph.
Does it make sense?
Well, sort of. You’ll need a lot of data either way.
I can see a couple issues with this current implementation. Firstly, if members catch onto the fact that mentions equate to some kind of points, you’re going to end up with spam. One way to combat this is to only count one mention per minute, so mass-spam is discouraged since you can only gain points once a minute. Another issue is that simply counting mentions is just one side of the story — counting the amount of messages a person sends might be more useful, and maybe a mix of both is an optimal solution for figuring out popularity.